web基础知识
本文最后更新于:2024年8月9日 晚上
记录Mmdn Web docs学习笔记~
互联网是如何工作的
互联网是一种将所有计算机连接在一起的方式,并确保无论发生什么,它们都能找到保持连接的方法。
IP地址:任何链接到网络的计算机都有一个唯一的地址来识别它,成为“IP地址”。
- IP代表Internet协议
- IP地址由四个数字组成,例如:
192.0.2.172
为了方便起见,使用域名为IP地址添加别名。(增加了可读性,例如google.com)
区分互联网和网络
互联网是一种技术基础设施,它允许数十亿台计算机连接在一起。在这些计算机中,某些计算机(称为 Web 服务器)可以向 Web 浏览器发送可理解的消息。
Internet 是一种基础设施,而 Web 是建立在基础设施之上的服务。
值得注意的是,还有其他一些服务建立在互联网之上,例如电子邮件和IRC。
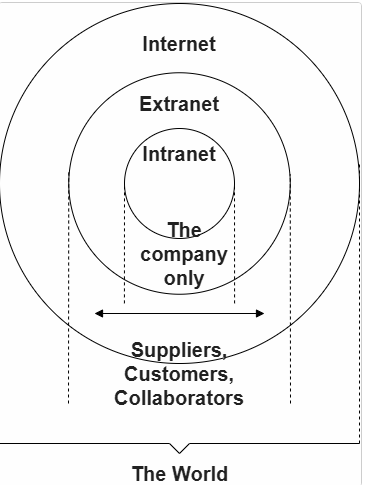
区分内联网和外联网
- Intranet 是仅限于特定组织的成员的专用网络。 它们通常用于为成员提供一个门户,以安全地访问共享资源、协作和通信。
- 例如,组织的 Intranet 可能托管用于共享部门或团队信息的网页、用于管理关键文档和文件的共享驱动器、 用于执行业务管理任务的门户,以及 Wiki、讨论板和消息传递系统等协作工具。
- Extranet 与 Intranet 非常相似,不同之处在于它们打开全部或部分专用网络,以便与其他组织共享和协作。 它们通常用于与与企业密切合作的客户和利益相关者安全可靠地共享信息。
- 通常,它们的功能类似于 Intranet 提供的功能:信息和文件共享、协作工具、讨论板等。
- Intranet 和 Extranet 都运行在与 Internet 相同的基础设施上,并使用相同的协议。 因此,授权成员可以从不同的物理位置访问它们。
网页、网站、网络服务器和搜索引擎有什么区别?
网页
可以在 Firefox、Google Chrome、Opera、Microsoft Edge 或 Apple Safari 等 Web 浏览器中显示的文档。这些通常也被称为“页面”,可由浏览器显示。
- 这些文档是用
HTML语言编写的。 - 网页可以嵌入各种不同类型的资源,例如:
样式信息— 控制页面的外观脚本— 增加页面的交互性媒体— 图像、声音和视频
- 浏览器还可以显示其他文档,例如 PDF 文件或图像,但术语
网页特指HTML 文档。 - 网络上可用的所有网页都可以通过唯一的地址访问。要访问页面,只需在浏览器地址栏中输入其地址。
网站
网网站是共享唯一域名的链接网页(及其相关资源)的集合,这些网页被组合在一起,通常以各种方式连接在一起。通常称为“网站”或“站点”。
- 给定网站的每个网页都提供明确的链接(大多数时候以可点击的文本部分的形式存在),允许用户从网站的一个页面移动到另一个页面。
- 请注意,也可以拥有单页网站:由单个网页组成的网站,该网页在需要时会动态更新新内容。
- 要访问网站,请在浏览器地址栏中输入其域名,浏览器将显示网站的主网页或主页
网页服务器
Web 服务器是托管一个或多个网站的计算机。“托管”意味着所有网页及其支持文件都可以在该计算机上使用。根据用户请求,Web 服务器将从它托管的网站将任何网页发送到任何用户的浏览器。
不要混淆网站和 Web 服务器。
- 例如,如果您听到有人说“我的网站没有响应”,这实际上意味着网络服务器没有响应,因此网站不可用。
- 由于 Web 服务器可以托管多个网站,因此术语 Web 服务器绝不用于指定网站,因为它可能会导致极大的混淆
- 如果我们说“我的 Web 服务器没有响应”,则意味着该 Web 服务器上的多个网站不可用。
搜索引擎
一种 Web 服务,可帮助您查找其他网页,例如 Google、Bing、Yahoo 或 DuckDuckGo。搜索引擎通常通过网络浏览器(例如,您可以直接在Firefox、Chrome等的地址栏中执行搜索引擎搜索)或通过网页(例如 bing.com 或 duckduckgo.com)访问。
- 搜索引擎是一种特殊类型的网站,可帮助用户从其他网站查找网页。
区分浏览器和搜索引擎
- 浏览器是一种检索和显示网页的软件;搜索引擎是一个帮助人们从其他网站找到网页的网站。
- 不要将基础设施(例如浏览器)与服务(例如搜索引擎)混淆。
- 之所以产生混淆,是因为当有人第一次启动浏览器时,浏览器会显示搜索引擎的主页。这是有道理的,因为很明显,您要用浏览器做的第一件事就是找到要显示的网页。
类比
让我们看一个简单的类比——公共图书馆。这是您在访问图书馆时通常会做的事情:
- 找到一个搜索索引,并查找您想要的书名。
- 记下图书的目录号。
- 转到包含该书的特定部分,找到正确的目录号,然后获取该书。
让我们将库与 Web 服务器进行比较:
- 该库就像一个 Web 服务器。它有几个部分,类似于托管多个网站的 Web 服务器。
- 图书馆的不同部分(科学、数学、历史等)就像网站一样。每个部分都像一个独特的网站(两个部分不包含相同的书籍)。
- 每个部分的书籍都像网页一样。一个网站可能有几个网页,例如,科学部分(网站)将有关于热、声音、热力学、静力学等的书籍(网页)。每个网页都可以在唯一的位置 (URL) 找到。
- 搜索索引就像搜索引擎。每本书在图书馆中都有自己独特的位置(两本书不能放在同一个地方),该位置由目录号指定。
URL:统一资源定位符
早在 1989 年,Web 的发明者 Tim Berners-Lee 就谈到了 Web 赖以存在的三大支柱:
- URL,一个跟踪 Web 文档的地址系统
- HTTP,一种传输协议,用于在给定文档的 URL 时查找文档
- HTML,一种允许嵌入超链接的文档格式
Web 上的一切都围绕着文档以及如何访问它们。Web 的最初目的是提供一种访问、阅读和浏览文本文档的简单方法。从那时起,Web 已经发展到提供对图像、视频和二进制数据的访问,但这些改进几乎没有改变三大支柱。
统一资源定位符 (URL) 是一个文本字符串,用于指定可以在 Internet 上找到资源(如网页、图像或视频)的位置。
在 HTTP 的上下文中,URL 称为“Web 地址”或“链接”。您的浏览器在其地址栏中显示 URL,例如:https://developer.mozilla.org
- 某些浏览器仅显示 URL 中“//”之后的部分,即域名。
URL 还可用于文件传输 (FTP)、电子邮件 (SMTP) 和其他应用程序。
URL的组成
以下是一些URL示例:
1 | |

可以将 URL 视为常规的邮政地址:
- Scheme 代表您要使用的邮政服务,Domain Name(域名)是城市或城镇,Port类似于邮政编码;
- 路径代表应将邮件投递的建筑物;这些参数代表额外的信息,例如建筑物中公寓的编号;
- 最后,锚点代表向其发送邮件的实际人。
Scheme
URL的第一部分是Scheme,它表示浏览器必须用于请求资源的协议。
- 协议是在计算机网络中交换或传输数据的固定方法。
- 通常对于网站,协议是
HTTPS或HTTP(其不安全版本)。- 寻址网页需要这两者之一,但浏览器也知道如何处理其他方案,例如(打开邮件客户端),因此,如果您看到其他协议,请不要感到惊讶。
mailto:
- 寻址网页需要这两者之一,但浏览器也知道如何处理其他方案,例如(打开邮件客户端),因此,如果您看到其他协议,请不要感到惊讶。
Authority
Authority通过://与Scheme分开,包括域 (e.) 和端口 (),用冒号分隔:://www.example.com80
- Domain Name:
指正在请求的 Web 服务器。通常这是一个域名,但也可以使用 IP 地址(但这很少见,因为它不太方便)。 - Port:
端口表示用于访问 Web 服务器上的资源的技术“门”。如果 Web 服务器使用 HTTP 协议的标准端口(HTTP 为 80,HTTPS 为 443)来授予对其资源的访问权限,则通常会省略它。- 不使用的Authority 的URL 示例是邮件客户端 。它包含一个Scheme,但不使用Authority。因此,冒号后面没有两个斜杠,仅充当方案和邮件地址之间的分隔符。mailto:foobar
Path to resouorce
/path/to/myfile.html是 Web 服务器上资源的路径。在 Web 的早期,像这样的路径表示 Web 服务器上的物理文件位置。如今,它主要是由 Web 服务器处理的抽象,没有任何物理现实。
Parameters
?key1=value1&key2=value2是提供给 Web 服务器的额外参数。这些参数是用符号分隔的键/值对列表。在返回资源之前,Web 服务器可以使用这些参数来执行额外的操作。每个 Web 服务器都有自己的参数规则。
Anchor
#SomewhereInTheDocument是资源本身的另一部分的锚点。
锚点代表资源内部的一种“书签”,为浏览器提供指示,以显示位于该“书签”位置的内容。
- 例如,在 HTML 文档上,浏览器将滚动到定义锚点的位置;在视频或音频文档上,浏览器将尝试转到锚点所代表的时间。
#后面的部分,也称为片段标识符,永远不会随请求一起发送到服务器。
使用URL
HTML 语言大量使用 URL:
- 使用
<a>元素创建指向其他文档的链接; - 通过各种元素(如
<link>或<script>将文档与其相关资源链接起来。 - 显示媒体,如图像(带有
<img>元素)、视频(带有<video>元素)、声音和音乐(带有<audio>元素)等; - 显示带有
<iframe>元素的其他 HTML 文档。
注意:在指定 URL 以将资源作为页面的一部分加载时,通常应仅使用 HTTP 和 HTTPS URL。
绝对URL与相对URL
URL 标准定义了两者 — 尽管它使用术语绝对 URL 字符串和相对 URL 字符串,以将它们与 URL 对象(它们是 URL 的内存表示形式)区分开来。
URL 的必需部分在很大程度上取决于使用 URL 的上下文。
在浏览器的地址栏中,URL 没有任何上下文,因此您必须提供一个完整(或绝对)的 URL,就像我们上面看到的一样。您不需要包含协议(浏览器默认使用 HTTP)或端口(仅当目标 Web 服务器使用某些不寻常的端口时才需要),但 URL 的所有其他部分都是必需的。
当在文档中使用 URL 时,例如在 HTML 页面中,情况会有所不同。由于浏览器已经拥有文档自己的 URL,因此它可以使用此信息来填充该文档中任何可用 URL 的缺失部分。我们可以通过仅查看 URL 的路径部分来区分绝对 URL 和相对 URL。如果 URL 的路径部分以
/字符开头,则浏览器将从服务器的顶部根目录获取该资源,而不引用当前文档给出的上下文。
例如:https://developer.mozilla.org/en-US/docs/Learn本身是一个绝对的 URL。它具有找到它指向的资源所需的所有必要部分。
- 相对于Scheme的 URL
仅缺少协议。浏览器将使用与用于加载托管该 URL 的文档相同的协议。//developer.mozilla.org/en-US/docs/Learn - Domain Name相对URL:
协议和域名都丢失。浏览器将使用与用于加载托管该 URL 的文档相同的协议和相同的域名。/en-US/docs/Learn - 子资源:
协议和域名缺失,浏览器将尝试在包含当前资源的子目录中查找文档。在这种情况下访问此 URL:.Common_questions/Web_mechanics/What_is_a_URL - 仅Auchor:
除锚外的所有部件都丢失。浏览器将使用当前文档的 URL 并替换或添加锚点部分。当您想要链接到当前文档的特定部分时,这很有用。#semantic_urls
超链接
由于人类可读,URL 已经让事情变得更容易,但是每当您想要访问文档时,都很难输入长 URL。这就是超链接彻底改变一切的地方。链接可以将任何文本字符串与 URL 关联起来,这样用户就可以通过激活链接立即访问目标文档。
超链接的类型
内部链接
两个网页之间的链接,如果两个网页属于同一个网站,则称为内部链接。- 没有内部链接,就没有网站这样的东西(当然,除非它是一个单页网站)。
外部链接
从您的网页到其他人的网页的链接。- 没有外部链接,就没有Web,因为Web是网页的网络。使用外部链接提供信息,而不是通过您的网页提供的内容。
传入链接
从他人的网页到您网站的链接。它与外部链接相反。- 请注意,当有人链接到您的网站时,您不必链接回去。
当你刚开始时,你不必那么担心外部和传入链接,但如果你想让搜索引擎找到你的网站,它们非常重要
锚
大多数链接将两个网页联系在一起。锚点将一个文档的两个部分联系在一起。当您点击指向锚点的链接时,您的浏览器会跳转到当前文档的另一部分,而不是加载新文档。
链接和搜索引擎
链接对用户和搜索引擎都很重要。每次搜索引擎抓取网页时,它们都会按照网页上可用的链接为网站编制索引。搜索引擎不仅通过跟踪链接来发现网站的各个页面,而且还使用链接的可见文本来确定哪些搜索查询适合到达目标网页。
链接会影响搜索引擎链接到您的网站的难易程度。
域名
任何连接到互联网的计算机都可以通过公共 IP 地址访问,无论是 IPv4 地址(例如 )还是 IPv6 地址(例如)。
IP地址便于计算机处理,但是不具有人类可读性,因此使用域名。
域名的结构
域名有一个简单的结构,由几个部分组成(可能只是一个部分、两个部分、三个部分……),用点分隔,从右到左阅读。其中每个部分都提供了有关整个域名的特定信息。
- TLD:顶级域名
顶级域名告诉用户域名背后的服务的一般目的。最通用的 TLD (, , ) 不需要 Web 服务满足任何特定标准,但一些 TLD 执行更严格的政策,因此更清楚地了解其目的。例如:.com,.org,.net- 本地顶级域名可以要求以特定语言提供服务或在特定国家/地区托管
- 它们应该以特定语言或国家/地区表示资源。
.us,.fr,.se
- 它们应该以特定语言或国家/地区表示资源。
- 一些顶级域名仅允许政府部门使用。
.gov - 一些顶级域名仅供教育和学术机构使用。
.edu - TLD可以包含特殊字符以及拉丁字符。TLD 的最大长度为 63 个字符,但大多数约为 2-3 个字符。
- 本地顶级域名可以要求以特定语言提供服务或在特定国家/地区托管
- 标签(或组件)
标签是 TLD 后面的内容。标签是一个不区分大小写的字符序列,长度从 1 到 63 个字符不等(字母和数字,-字符) - 二级域 (SLD)
位于 TLD 正前方的标签。- 一个域名可以有许多标签(或组件)。形成域名不是强制性的,也没有必要有 3 个标签。
- 例如,
informatics.ed.ac.uk是一个有效的域名。 - 对于您控制的任何域(例如
mozilla.org),您可以创建“子域”,每个子域都有不同的内容,例如developer.mozilla.org、support.mozilla.org或bugzilla.mozilla.org
购买域名
不能“永久购买域名”。这是为了让未使用的域名最终可供其他人再次使用。如果每个域名都被购买,网络很快就会填满未使用的域名,这些域名被锁定,任何人都无法使用。
取而代之的是,您需要为使用域名一年或更长时间的权利付费。您可以续展您的权利,并且您的续展优先于其他人的申请。但是您永远不会拥有该域名。
- 称为注册商的公司使用域名注册机构来跟踪将您与您的域名联系起来的技术和管理信息。
- 对于某些域名,它可能不是负责跟踪的注册商。
- 例如,下面的每个域名都由亚马逊管理。
.fire
- 例如,下面的每个域名都由亚马逊管理。
DNS
DNS数据库存储在全球的每个DNS服务器上,所有这些服务器都是指一些称为“权威名称服务器”或“顶级DNS服务器”的特殊服务器
- 这些服务器就像管理系统的老板服务器。
- 每当您的注册商为给定域创建或更新任何信息时,都必须在每个 DNS 数据库中刷新该信息。每个知道给定域的DNS服务器都会将信息存储一段时间,然后自动失效,然后刷新(DNS服务器查询权威服务器并从中获取更新的信息)。因此,了解此域名的DNS服务器需要一些时间才能获取最新信息。
DNS请求如何工作?
正如我们已经看到的,当您想在浏览器中显示网页时,输入域名比输入 IP 地址更容易。让我们看一下过程:
- 在浏览器的位置栏中输入内容。
mozilla.org - 您的浏览器会询问您的计算机是否已经识别此域名标识的 IP 地址(使用
本地 DNS 缓存)。- 如果是这样,则名称将转换为 IP 地址,浏览器将与 Web 服务器协商内容。故事到此结束。
- 如果您的计算机不知道名称后面是哪个 IP,它会继续询问 DNS 服务器,该服务器的工作就是告诉您的计算机哪个 IP 地址与每个注册域名匹配。
- 现在计算机知道请求的 IP 地址,您的浏览器可以与 Web 服务器协商内容。
Web服务器
Web 服务器可以指硬件或软件,或者两者协同工作。
- 在硬件方面,Web 服务器是存储 Web 服务器软件和网站组件文件(例如,HTML 文档、图像、CSS 样式表和 JavaScript 文件)的计算机。Web 服务器连接到 Internet,并支持与连接到 Web 的其他设备进行物理数据交换。
- 在软件方面,Web 服务器包括几个部分,用于控制 Web 用户访问托管文件的方式。至少,这是一个 HTTP 服务器。
- HTTP 服务器是理解 URL(网址)和 HTTP(浏览器用于查看网页的协议)的软件。HTTP服务器可以通过其存储的网站的域名进行访问,并将这些托管网站的内容传送到最终用户的设备。
在最基本的层面上,每当浏览器需要托管在 Web 服务器上的文件时,浏览器都会通过 HTTP 请求该文件。当请求到达正确的(硬件)Web 服务器时,(软件)HTTP 服务器接受请求,找到请求的文档,并将其发送回浏览器,也通过 HTTP。(如果服务器找不到请求的文档,它将返回 404 响应。
静态or动态Web服务器
静态 Web 服务器或堆栈由计算机(硬件)和 HTTP 服务器(软件)组成。我们称其为“静态”,因为服务器将其托管文件按原样发送到您的浏览器。
动态 Web 服务器由静态 Web 服务器和额外的软件组成,最常见的是
应用程序服务器和数据库。- 我们称其为“动态”,因为应用程序服务器在通过 HTTP 服务器将内容发送到您的浏览器之前会更新托管文件。
- 例如,为了生成在浏览器中看到的最终网页,应用程序服务器可能会使用数据库中的内容填充 HTML 模板。像MDN或Wikipedia这样的网站有数以千计的网页。通常,这类网站仅由几个 HTML 模板和一个巨大的数据库组成,而不是由数千个静态 HTML 文档组成。通过此设置,可以更轻松地维护和交付内容。
托管文件
首先,Web 服务器必须存储网站的文件,即所有 HTML 文档及其相关资产,包括图像、CSS 样式表、JavaScript 文件、字体和视频。
从技术上讲,您可以将所有这些文件托管在自己的计算机上,但将所有文件存储在专用的 Web 服务器上要方便得多,因为:
- 专用 Web 服务器通常更可用(启动并运行)。
- 排除停机时间和系统故障,专用的 Web 服务器始终连接到 Internet。
- 专用 Web 服务器可以始终具有相同的 IP 地址。这称为专用 IP 地址。(并非所有 ISP 都为家庭线路提供固定的 IP 地址。
- 专用 Web 服务器通常由第三方维护。
通过 HTTP 进行通信
Web 服务器提供对 HTTP (Hypertext Transfer Protocol) 的支持。顾名思义,HTTP指定了如何在两台计算机之间传输超文本(链接的Web文档)。
协议是两台计算机之间通信的一组规则。HTTP 是一种
文本的无状态协议。- 所有命令都是纯文本的,并且人类可读。
- 服务器和客户端都不记得以前的通信。例如,仅依赖 HTTP,服务器无法记住您输入的密码,也无法记住未完成事务的进度。您需要一个应用程序服务器来完成此类任务。
通常只有客户端才会发出 HTTP 请求,并且只向服务器发出。
- 通过 HTTP 请求文件时,客户端必须提供文件的 URL。
服务器响应客户端的 HTTP 请求。服务器还可以通过一种称为服务器推送的机制,在请求数据之前将数据填充到客户端缓存中。
- Web 服务器必须响应每个 HTTP 请求,至少要回答一条错误消息。
在 Web 服务器上,HTTP 服务器负责处理和应答传入的请求。
- 收到请求后,HTTP 服务器会检查请求的 URL 是否与现有文件匹配。
- 如果是这样,Web 服务器会将文件内容发送回浏览器。如果没有,服务器将检查它是否应该为请求动态生成文件(请参阅静态与动态内容)。
- 如果这两个选项都不可行,Web 服务器将向浏览器返回一条错误消息,最常见的是
404 Not Found。- 404 错误非常普遍,以至于一些网页设计师投入了大量的时间和精力来设计 404 错误页面。
Web入门
处理文件
网站应该使用什么结构
在我们创建的任何网站项目中,最常见的是一个主页 HTML 文件和包含图像、样式文件和脚本文件的文件夹。
index.html:这个文件一般会包含主页内容,也就是人们第一次进入网站时看到的文字和图片。- 使用文本编辑器,创建一个名为index.html的新文件,并将其保存在test-site文件夹内。
images文件夹:这个文件夹包含网站上使用的所有图片。- 在 test-site 文件夹内创建一个名为 images 的文件夹。
styles文件夹:这个文件夹包含用于设置内容样式的 CSS 代码(例如,设置文本和背景颜色)。- 在你的 test-site 文件夹内创建一个名为 styles 的文件夹。
scripts文件夹:这个文件夹包含所有用于向网站添加交互功能的 JavaScript 代码(例如,点击时加载数据的按钮)。- 在 test-site 文件夹内创建一个名为 scripts 的文件夹。
备注:在 Windows 上你可能看不到文件扩展名,因为 Windows 有一个默认开启的隐藏已知文件类型的扩展名的选项。一般来说,你可以通过 Windows 资源管理器,选择文件夹选项选项,取消勾选隐藏已知文件类型的扩展名复选框,然后点击确认将其关闭。
文件路径
为使文件间正常交互,应为每个文件提供访问路径,所以一个文件知道另一个文件的位置。
文件路径的一些通用规则:
- 若引用的目标文件与 HTML 文件同级,只需直接使用文件名,例如:my-image.jpg。
- 要引用子目录中的文件,请在路径前面写上目录名,再加上一个正斜杠。例如:subdirectory/my-image.jpg。
- 若引用的目标文件位于 HTML 文件的上级,需要加上两个点。
- 举个例子,如果 index.html 在 test-site 的一个子文件夹内,而 my-image.jpg 在 test-site 内,你可以使用../my-image.jpg 从 index.html 引用 my-image.jpg。
- 以上方法可以随意组合,比如:../subdirectory/another-subdirectory/my-image.jpg。
Windows 的文件系统使用反斜杠而不是正斜杠,例如:C:\Windows。这在 HTML 中并不重要——即使你在 Windows 系统上进行开发,你也应该在代码中使用正斜杠。