python
本文最后更新于:2024年8月3日 下午
记录python的学习过程~
pycharm配置python开发环境
参考:
https://blog.csdn.net/yuhui_2000/article/details/109185168
基本知识
1. 注释
- 单行注释以 # 号开头
- 多行注释用两个三引号```包含起来
1
2
3
4
51. '''
2. 第一行注释
3. 第二行注释
4. '''
5. print('Hello,World!')
2. Python的行与缩进
- 使用缩进来表示代码块,不需要像C或者C++一样使用大括号。
- 缩进的空格数可变,但是同一个代码块的语句必须包含相同的缩进空格数
- 使用四个空格来表示一个缩进层级
1
2
3
4
5if x > 0:
print("x is positive")
print("positive number")
else:
print("x is zero or negative")
3. 多行语句
Python 通常是一行写完一条语句;长语句可通过反斜杠(\)来实现多行语句。
python的print()函数中参数end=’ ‘默认为\n,所以会自动换行。
- end=’ ‘ 表示不换行
- end=’\t’——表示缩进,就是按一下Tab键
- end=’\n’——相当于换行
- end=’\r’ 返回行首,最后一个字符的输入会将之前的字符全部覆盖掉
4. 等待用户输入:input() 函数
1 | |
5. 变量
- 变量命名和赋值:Python 的变量无须提前声明,赋值的同时也就声明了变量。
eg:a = 42 - 查询关键字:keyword模块中的kwlist是一个列表,存放了Python中所有的关键字(str格式)。
1
2
3
4
5
6
7#列出所有关键字
import keyword
keyword.kwlist
#判断是否为关键字,为真,返回True,为假,返回False
keyword.iskeyword("break")
keyword.iskeyword("breaka")
6. 数据类型
Python 中拥有 6 大数据类型:number、string、list(列表)、tuple(元组)、sets (集合)、dictionary(字典)。
数字
类型:int、float、bool、complex (复数)
使用 type() 函数来查看数字类型
1 | |
运算类型
1 | |
math 模块、cmath 模块:
数学运算常用的函数基本都在 math 模块、cmath 模块中。
要使用 math 或 cmath 函数必须先导入:
1 | |
更多数学函数、三角函数、pi,e、随机数函数等,详细参考:
https://www.runoob.com/python/python-numbers.html
字符串
单引号与双引号的作用一样,但是当引号里包含单引号时,则该引号需使用双引号;三引号可以指示一个多行的字符串,也可以在三引号中自由使用单引号和双引号
1 | |
tips:
使用双反斜杠(
\\)来表示反斜杠本身,而 \n 表示换行想要指示某些不需要使用转义符进行特别处理的字符串,那么需要指定一个原始字符串。原始字符串通过给字符串加上前缀 r 或 R:
1
2
3
4
5
6
7
8
9
10
11>>> s = r"换行符是\n。"
>>> print(s)
换行符是\n。
>>> s = 'it\'s me'
>>> s
"it's me"
>>> s = "换行符是\\n。"
>>> print(s)
换行符是\n。详细可参考:https://blog.csdn.net/yawei_liu1688/article/details/108364192
字符串的截取(切片) :
字符串常量[start_index:end_index+1](左闭右开)1
2
3
41. str = 'Lingyi'
2. print(str[0]) #输出结果为L
3. print(str[1:4]) #输出结果为ing
4. print(str[-1]) #输出结果为i
- [:] 这种形式 就是 从哪截取到哪里 如果是负数 就从后往前找
- [::] 这种形式 第一个 :代表处理后的字符串,第二个 : 代表间隔截取,正数正向输出,负数代表逆向输出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16str = '0123456789'
print("str[0:3]:"+str[0:3]) # 正向截取字符串 0~3(不包含3),即 012
print("str[:]:"+str[:]) # 正向输出所有字符串,即0123456789
print("str[6:]:"+str[6:]) # 正向输出字符,从 6 ~ 结束 即 6789
print("str[:-3]:"+str[:-3]) # 正向输出,从开始 ~ 倒数第第3个字符(不含第3个)即 0123456
print("str[2]:"+str[2]) #输出第3个字符 即 2
print("str[:-1]:"+str[:-1]) # 正向输出,从开始 ~ 倒数第第1个字符(不含第1个)即 012345678
print("str[-1]:"+str[-1]) # 输出最后一个字符 即 9
print("str[-3:-1]:"+str[-3:-1]) #逆序输出,从倒数第 3 ~ 倒数第 1 (不含) 即 78
print("str[-3:]:"+str[-3:]) # 逆序输出,从倒数第 3 ~ 最后 即 789
print("str[::-1]:"+str[::-1]) # 逆序输出,连续输出所有字符串,即 9876543210
print("str[::-2]:"+str[::-2]) # 逆序输出,从最后一个开始,每隔2个字符串输出一个 97531
print("str[::1]:"+str[::1]) # 正序输出,连续输出所有字符串,即 0123456789
print("str[::2]:"+str[::2]) # 正序输出,从第一个开始,每隔2个字符串输出一个即 02468
print("str[:-2:4]:"+str[:-2:4]) # 正序输出,从第一个开始,每隔4个字符输出一个 即 04
print("str[1:-2:4]:"+str[1:-2:4])# 正序输出,从第二个开始,每隔4个字符输出一个 即 15
- 不同数据类型可以相互转换
1
2
3
41. num = 1
2. string = '1'
3. num2 = int(string)
4. print(num+num2) +用在字符串中间是连接符,用在数值中间是运算符1
2
3
4
5
6
7
8
9
10
11#运算符,结果为3
1. a = 1
2. b = 2
3. c = a+b
4. print(c)
#连接符,结果为ab
1. a = 1
2. b = 2
3. c = 'a'+'b'
4. print(c)- 字符串的驻留机制:https://zhuanlan.zhihu.com/p/35362912
- 字符串内建函数:实现了 string 模块的大部分方法。
详细参考:https://www.runoob.com/python/python-strings.html
列表
列表是任意对象的有序集合,元素之间用逗号隔开。这里的任意对象,包括列表嵌套列表。
- 列表删除操作:
del 目标 或 del(目标)\1
2
3
4
5
6
7
8
9# 删除列表
list1 = ['python', 'java', 'php']
# 2种写法
del list1
# del(list1 )
# 删除指定数据
list2 = ['python', 'java', 'php']
del list2[0]pop()
删除指定下标的数据,如果不指定下标,默认删除最后一个数据,无论是按照下标还是删除最后一个,pop函数都会返回这个被删除的数据remove(数据)1
2
3list1 = ['python', 'java', 'php']
list1.remove('python')
# 也可以写成:list1.remove(list1[0])clear(列表名):清空列表
- 更新列表:使用
append()添加列表项 - 列表脚本操作符:
列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表。 - 常用列表函数:
https://www.runoob.com/python/python-lists.html
元组
Python 的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号。
- 删除元组:
del 元组名 - 对元组连接组合
- 元组运算符(进行组合和复制)
- 元组索引,截取
- 无关闭分隔符:任意无符号的对象,以逗号隔开,默认为元组
- 元组内置函数:
https://www.runoob.com/python/python-tuples.html
字典
一种可变容器模型,且可存储任意类型对象。dict 作为 Python 的关键字和内置函数,字典的变量名不建议命名为 dict。
1 | |
字典值可以没有限制地取任何 python 对象,既可以是标准的对象,也可以是用户定义的,但键不行。
- 键一般是唯一的,如果重复最后的一个键值对会替换前面的,值不需要唯一。
- 值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组。
- 访问字典的值
1
2
3
4
5
6#!/usr/bin/python
tinydict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
print "tinydict['Name']: ", tinydict['Name']
print "tinydict['Age']: ", tinydict['Age'] - 修改字典
1
2
3
4tinydict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
tinydict['Age'] = 8 # 更新
tinydict['School'] = "RUNOOB" # 添加 - 删除字典元素
1
2
3del tinydict['Name'] # 删除键是'Name'的条目
tinydict.clear() # 清空字典所有条目
del tinydict # 删除字典 - 字典内置函数&方法
https://www.runoob.com/python/python-dictionary.html
7. 日期与时间
Python 提供了一个 time 和 calendar 模块可以用于格式化日期和时间。
时间间隔是以秒为单位的浮点小数。每个时间戳都以自从1970年1月1日午夜(历元)经过了多长时间来表示。
time.time() 用于获取当前时间戳
struct_time元组
很多Python函数用一个元组装起来的9组数字处理时间:
html
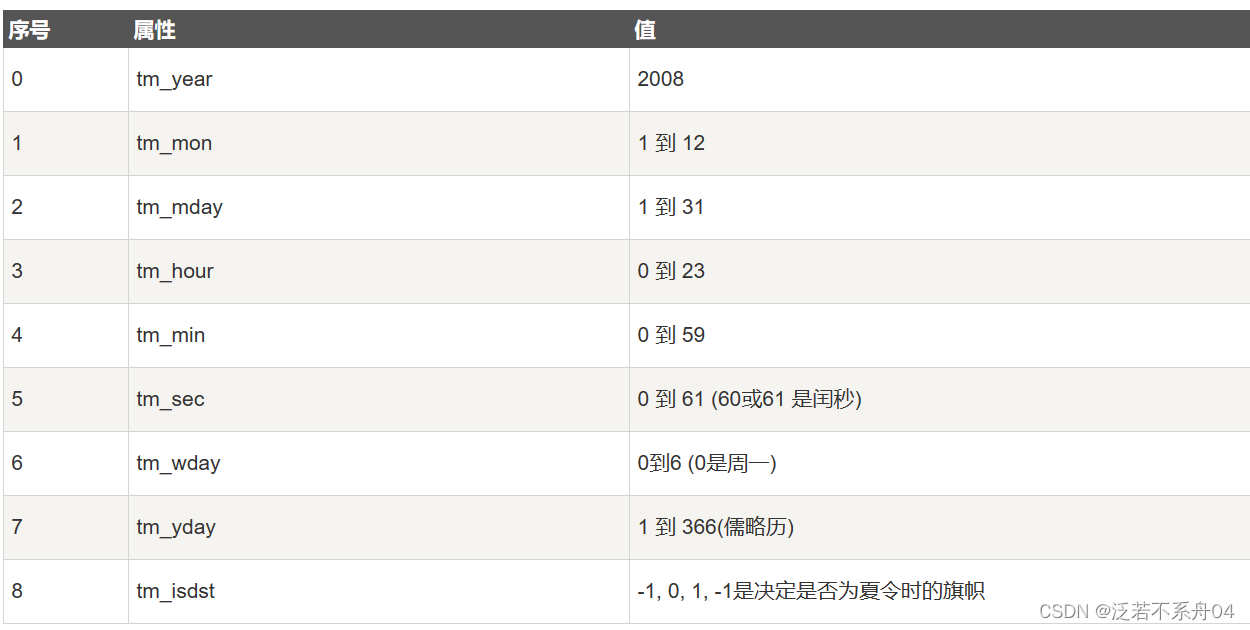
获取当前时间:
从返回浮点数的时间戳方式向时间元组转换,只要将浮点数传递给如localtime之类的函数
1 | |
实例输出结果为:
1 | |
获取格式化的时间: asctime()
1 | |
实例输出结果为:
1 | |
格式化日期
使用 time 模块的 strftime 来格式化日期 :time.strftime(format[, t])
1 | |
日期格式化符号解释:https://www.runoob.com/python/python-date-time.html
获取某月日历:引入calendar模块
1 | |
输出结果:
1 | |
补充: python中关于时间和日期方面的模块有:Time 模块、Calendar模块、datetime模块、pytz模块、dateutil模块。
详细参考:https://www.runoob.com/python/python-date-time.html
8. 语句
条件语句
Python程序语言指定任何非0和非空(null)值为true,0 或者 null为false
- python 并不支持 switch 语句,所以多个条件判断,只能用 elif 来实现。
如果判断需要多个条件需同时判断时,可以使用 or (或),表示两个条件有一个成立时判断条件成功;使用 and (与)时,表示只有两个条件同时成立的情况下,判断条件才成功。1
2
3
4
5
6
7
8if 判断条件1:
执行语句1……
elif 判断条件2:
执行语句2……
elif 判断条件3:
执行语句3……
else:
执行语句4…… - 也可以在同一行的位置上使用if条件判断语句
1
2
3var = 100
if ( var == 100 ) : print "变量 var 的值为100"
循环语句
基本语法:
1
2
3
4
5
6
7# while循环
while 判断条件(condition):
执行语句(statements)……
# for循环
for iterating_var in sequence:
statements(s)continue 用于跳过该次循环,break 则是用于退出循环。
此外”判断条件”还可以是个常值,表示循环必定成立。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# continue 和 break 用法
i = 1
while i < 10:
i += 1
if i%2 > 0: # 非双数时跳过输出
continue
print i # 输出双数2、4、6、8、10
i = 1
while 1: # 循环条件为1必定成立
print i # 输出1~10
i += 1
if i > 10: # 当i大于10时跳出循环
break无限循环:如果条件判断语句永远为 true,循环将会无限的执行下去
可以使用CTRL+C来中断无限循环。循环使用 else 语句
- while … else 在循环条件为 false 时执行 else 语句块
1
2
3
4
5
6count = 0
while count < 5:
print count, " is less than 5"
count = count + 1
else:
print count, " is not less than 5" - for循环
1
2
3
4
5
6
7
8for num in range(10,20): # 迭代 10 到 20 之间的数字
for i in range(2,num): # 根据因子迭代
if num%i == 0: # 确定第一个因子
j=num/i # 计算第二个因子
print ('%d 等于 %d * %d' % (num,i,j))
break # 跳出当前循环
else: # 循环的 else 部分
print ('%d 是一个质数' % num)
- 简单语句组
如果while 循环体中只有一条语句,可以将该语句与while写在同一行中1
2
3flag = 1
while (flag): print 'Given flag is really true!' - 通过序列索引迭代
1
2
3
4fruits = ['banana', 'apple', 'mango']
for index in range(len(fruits)):
print ('当前水果 : %s' % fruits[index])
pass语句
pass 是空语句,是为了保持程序结构的完整性,用做占位语句。
1 | |
9. 运算符
算术运算符(略)
比较运算符(略)
赋值运算符(略)
参考:https://www.runoob.com/python/python-operators.html
位运算符
按位运算符是把数字看作二进制来进行计算的
| 运算符 | 解释 | 作用 |
|---|---|---|
| & | 按位与运算符 | 参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0 |
| I | 按位或运算符 | 只要对应的二个二进位有一个为1时,结果位就为1 |
| ^ | 按位异或运算符 | 当两对应的二进位相异时,结果为1 |
| ~ | 按位取反运算符 | 对数据的每个二进制位取反,即把1变为0,把0变为1 。~x 类似于 -x-1 |
| << | 左移动运算符 | 运算数的各二进位全部左移若干位,由 << 右边的数字指定了移动的位数,高位丢弃,低位补0。 |
| >> | 右移动运算符 | 把”>>”左边的运算数的各二进位全部右移若干位,>> 右边的数字指定了移动的位数 |
逻辑运算符
- and
- or
- not
成员运算符
- in
- not in
1
2
3
4
5
6
7
8
9
10
11
12
13
14a = 10
list = [1, 2, 3, 4, 5 ];
if ( a in list ):
print "变量 a 在给定的列表中 list 中"
else:
print "变量 a 不在给定的列表中 list 中"
# 修改变量 a 的值
a = 2
if ( a in list ):
print "变量 a 在给定的列表中 list 中"
else:
print "变量 a 不在给定的列表中 list 中"
身份运算符
用于比较两个对象的存储单元(本质是判断指针)
- is
- is not
tips:is 与 == 区别 :
is 用于判断两个变量引用对象是否为同一个(同一块内存空间), == 用于判断引用变量的值是否相等。
10. 函数
自定义函数
语法:
1 | |
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
参数传递
在 python 中,类型属于对象,变量是没有类型的:
1 | |
以上代码中,[1,2,3] 是 List 类型,”Runoob” 是 String 类型,而变量 a 是没有类型,她仅仅是一个对象的引用(一个指针),可以是 List 类型对象,也可以指向 String 类型对象。
可更改(mutable)与不可更改(immutable)对象:
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象。不可变类型:变量赋值 a=5 后再赋值 a=10,这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃,不是改变a的值,相当于新生成了a。
可变类型:变量赋值 la=[1,2,3,4] 后再赋值 la[2]=5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了。
python 函数的参数传递:
不可变类型:类似 c++ 的值传递,如 整数、字符串、元组。如fun(a),传递的只是a的值,没有影响a对象本身。比如在 fun(a)内部修改 a 的值,只是修改另一个复制的对象,不会影响 a 本身。
可变类型:类似 c++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后fun外部的la也会受影响
使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值。
调用函数时,默认参数的值如果没有传入,则被认为是默认值
参数默认值在函数声明时设置
不定长参数
1 | |
加了星号(*)的变量名会存放所有未命名的变量参数
示例:
1 | |
匿名参数
1 | |
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
示例:运行结果:1
2
3
4
5
6# 可写函数说明
sum = lambda arg1, arg2: arg1 + arg2
# 调用sum函数
print "相加后的值为 : ", sum( 10, 20 )
print "相加后的值为 : ", sum( 20, 20 )1
2相加后的值为 : 30
相加后的值为 : 40
变量作用域
- 全局变量
- 局部变量
11.python的版本迭代备注
关于设置Python解释器的默认字符编码为UTF-8
一些开源项目里面的python代码会写成:
1 | |
但Python 3中已经移除了sys.setdefaultencoding()函数,因为它会导致潜在的问题,特别是与第三方库的兼容性。
在Python 3中,字符串默认使用Unicode编码(UTF-8),而且不再需要显式地设置默认编码,直接使用Unicode字符串而不用担心编码问题。
decode( )和encode( )
在Python 3中,decode()方法用于将字节转换为字符串,而encode()方法用于将字符串转换为字节
进阶部分
1. 模块
Python 模块(Module),是一个 Python 文件,以 .py 结尾,包含了 Python 对象定义和Python语句。
模块能够有逻辑地组织Python 代码段。把相关的代码分配到一个模块里能让代码更好用,更易懂。
模块能定义函数,类和变量,模块里也能包含可执行的代码。
模块的引入
1 | |
一个模块只会被导入一次,不管你执行了多少次import。这样可以防止导入模块被一遍又一遍地执行。
搜索路径和环境变量
https://www.runoob.com/python/python-modules.html
命名空间和作用域
命名空间是一个包含了变量名称们(键)和它们各自相应的对象们(值)的字典。
一个 Python 表达式可以访问局部命名空间和全局命名空间里的变量。如果一个局部变量和一个全局变量重名,则局部变量会覆盖全局变量。如果要给函数内的全局变量赋值,必须使用 global 语句:global VarName
dir()函数
排好序的字符串列表,内容是一个模块里定义过的名字。
返回的列表容纳了在一个模块里定义的所有模块,变量和函数。
globals() 和 locals() 函数、reload() 函数
https://www.runoob.com/python/python-modules.html
Python中的包
包是一个分层次的文件目录结构,它定义了一个由模块及子包,和子包下的子包等组成的 Python 的应用环境。
简单来说,包就是文件夹,但该文件夹下必须存在 init.py 文件, 该文件的内容可以为空。init.py 用于标识当前文件夹是一个包。
更多可以参考:
https://www.runoob.com/python3/python3-module.html
2. File(文件) 方法
读取键盘输入
- raw_input函数
raw_input([prompt]) 函数从标准输入读取一个行,并返回一个字符串(去掉结尾的换行符) - input函数
input([prompt]) 函数和 raw_input([prompt]) 函数基本类似,但是 input 可以接收一个Python表达式作为输入,并将运算结果返回示例:1
2str = input("请输入:")
print "你输入的内容是: ", str1
2请输入:[x*5 for x in range(2,10,2)]
你输入的内容是: [10, 20, 30, 40]
打开、关闭和读写文件
open函数 :打开一个文件,创建一个file对象
file object = open(file_name ,[access_mode],[buffering])- file_name:file_name变量是一个包含了你要访问的文件名称的字符串值
- access_mode:access_mode决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)
- buffering:如果buffering的值被设为0,就不会有寄存。如果buffering的值取1,访问文件时会寄存行。如果将buffering的值设为大于1的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认
File对象的属性
| 属性 | 描述 |
|---|---|
| file.closed | 返回true如果文件已被关闭,否则返回false |
| file.mode | 返回被打开文件的访问模式 |
| file.name | 返回文件的名称 |
| file.softspace | 如果用print输出后,必须跟一个空格符,则返回false;否则返回true |
close()函数
fileObject.close():
刷新缓冲区里任何还没写入的信息,并关闭该文件,这之后便不能再进行写入write()函数
fileObject.write(string):将字符串写入一个打开的文件- Python字符串可以是二进制数据,而不是仅仅是文字。
- write()方法不会在字符串的结尾添加换行符(‘\n’)。
read()函数
fileObject.read([count]):从一个打开的文件中读取一个字符串- 被传递的参数是要从已打开文件中读取的字节计数
- 从文件的开头开始读入,如果没有传入count,它会尝试尽可能多地读取更多的内容,很可能是直到文件的末尾
示例:运行结果 :1
2
3
4
5
6
7# 打开一个文件
fo = open("foo.txt", "w")
fo.write( "www.runoob.com!\nVery good site!\n")
str = fo.read(10)
print "读取的字符串是 : ", str
# 关闭打开的文件
fo.close()读取的字符串是 : www.runoob
文件定位
tell():返回文件内的当前位置,下一次的读写会发生在文件开头这么多字节之后seek(offset,[from]):改变当前文件的位置- offset变量表示要移动的字节数
- from变量指定开始移动字节的参考位置
- 如果from设为0,将文件的开头作为移动字节的参考位置。
如果设为1,则使用当前的位置作为参考位置。
如果设为2,那么该文件的末尾将作为参考位置。运行结果:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 打开一个文件
fo = open("foo.txt", "r+")
str = fo.read(10)
print "读取的字符串是 : ", str
# 查找当前位置
position = fo.tell()
print "当前文件位置 : ", position
# 把指针再次重新定位到文件开头
position = fo.seek(0, 0)
str = fo.read(10)
print "重新读取字符串 : ", str
# 关闭打开的文件
fo.close()1
2
3读取的字符串是 : www.runoob
当前文件位置 : 10
重新读取字符串 : www.runoob
重命名和删除文件
Python的os模块提供了执行文件处理操作的方法,比如重命名和删除文件。
要使用这个模块,必须先 import os。
- os.rename(current_file_name, new_file_name)
重命名文件 - os.remove(file_name)
删除文件
Python里的目录
- os.mkdir(“newdir”)
在当前目录下创建新的目录 - os.chdir(“newdir”)
改变当前的目录1
2
3
4import os
# 将当前目录改为"/home/newdir"
os.chdir("/home/newdir") - os.getcwd()
显示当前的工作目录 - os.rmdir(‘dirname’)
删除目录,目录名称以参数传递,目录的完全合规的名称必须被给出,否则会在当前目录下搜索该目录。
更多参考:https://www.runoob.com/python/file-methods.html
with语句
用于简化资源管理的一种结构。它允许在代码块中打开一个资源(例如文件、网络连接、数据库连接等),并在使用完毕后自动关闭资源,无需显式地调用关闭方法。
1 | |
expression通常是一个返回可上下文管理器(context manager)的表达式,而可上下文管理器是一个具有
__enter__()和__exit__()方法的对象。__enter__()方法在进入with代码块时被调用,它负责设置资源,例如打开文件或建立网络连接,并返回相关的资源对象。而__exit__()方法在退出with代码块时被调用,它负责释放资源,例如关闭文件或断开网络连接。
在with语句块中可以使用资源对象,并在代码块执行完毕后,Python会自动调用__exit__()方法来释放资源,即使在代码块中发生了异常也会执行。这样可以确保资源的正确关闭,避免资源泄漏。
常见例子:使用with来打开文件
1 | |
在这个例子中,open()函数返回一个文件对象,它是一个上下文管理器。with open('example.txt', 'r') as file:会打开名为example.txt的文件,并将文件对象赋值给file变量。在代码块中,我们可以使用file对象读取文件内容。不论代码块是否抛出异常,with语句执行完毕后,文件对象会被自动关闭,无需显式调用file.close()方法。
readline( )函数
用于从文件对象中逐行读取数据,用于读取文件的一行内容,并返回一个字符串,包含了该行的内容(包括行尾的换行符 \n)。
每次调用readline(),都会读取文件当前位置的下一行,并将文件指针移动到下一行的开头,直到文件末尾。
当文件对象的指针移动到文件末尾后,再次调用readline()会返回空字符串,表示文件已经读取完毕。因此,在使用readline()时,通常使用循环来逐行读取文件的内容,直到返回空字符串为止,标志文件的末尾。
1 | |
strip()函数
用于去除字符串首尾的指定字符(默认是空格和换行符)或空白字符。它返回一个新的字符串,该字符串是去除了首尾指定字符后的原始字符串。
语法格式:
1 | |
其中,string是要操作的字符串,而chars是可选参数,用于指定需要去除的字符集合。如果不提供chars参数,则默认去除字符串首尾的空白字符(空格、制表符、换行符等)。
示例:
1 | |
3. 内置函数
https://www.runoob.com/python/python-built-in-functions.html
4. 异常处理
try….except…else
1 | |
当开始一个try语句后,python就在当前程序的上下文中作标记,这样当异常出现时就可以回到这里,try子句先执行,接下来会发生什么依赖于执行时是否出现异常。
如果当try后的语句执行时发生异常,python就跳回到try并执行第一个匹配该异常的except子句,异常处理完毕,控制流就通过整个try语句(除非在处理异常时又引发新的异常)。
如果在try后的语句里发生了异常,却没有匹配的except子句,异常将被递交到上层的try,或者到程序的最上层(这样将结束程序,并打印默认的出错信息)。
如果在try子句执行时没有发生异常,python将执行else语句后的语句(如果有else的话),然后控制流通过整个try语句。
使用except而不带任何异常类型
1 | |
使用except而带多种异常类型
1 | |
try-finally 语句
无论是否发生异常都将执行最后的代码
异常的参数
1 | |
一个异常可以带上参数,可作为输出的异常信息参数。
可以通过except语句来捕获异常的参数。
- 变量接收的异常值通常包含在异常的语句中。在元组的表单中变量可以接收一个或者多个值。元组通常包含错误字符串,错误数字,错误位置。
触发异常
raise [Exception, [args,[traceback]]]
- Exception 是异常的类型(例如,NameError)参数标准异常中任一种
- args 是自已提供的异常参数
- 最后一个参数是可选的(在实践中很少使用),如果存在,跟踪异常对象
示例:tips:为了能够捕获异常,”except”语句必须有用相同的异常来抛出类对象或者字符串。1
2
3
4def functionName( level ):
if level < 1:
raise Exception("Invalid level!", level)
# 触发异常后,后面的代码就不会再执行
例如我们捕获以上异常,”except”语句如下所示:
1 | |
用户自定义异常
通过创建一个新的异常类,程序可以命名它们自己的异常。异常应该是典型的继承自Exception类,通过直接或间接的方式。
https://www.runoob.com/python/python-exceptions.html
5.断言
https://blog.csdn.net/zhaofuxiang/article/details/53379394
6.推导式
Python 推导式是一种独特的数据处理方式,可以从一个数据序列构建另一个新的数据序列的结构体
列表推导式
1 | |
- out_exp_res:列表生成元素表达式,可以是有返回值的函数。
- for out_exp in input_list:迭代 input_list 将 out_exp 传入到 out_exp_res 表达式中。
- if condition:条件语句,可以过滤列表中不符合条件的值。
字典推导式
1 | |
集合推导式
1 | |
元组推导式(生成器表达式)
元组推导式可以利用 range 区间、元组、列表、字典和集合等数据类型,快速生成一个满足指定需求的元组。
1 | |
元组推导式和列表推导式的用法也完全相同,只是元组推导式是用 ( ) 圆括号将各部分括起来,而列表推导式用的是中括号 [ ],另外元组推导式返回的结果是一个生成器对象。
7. 面向对象
面向对象的基本特征:
- 类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。
对象是类的实例。 - 方法:类中定义的函数。
- 类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
- 数据成员:类变量或者实例变量用于处理类及其实例对象的相关的数据。
- 方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
- 局部变量:定义在方法中的变量,只作用于当前实例的类。
- 实例变量:在类的声明中,属性是用变量来表示的,这种变量就称为实例变量,实例变量就是一个用 self 修饰的变量。
- 继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类。
- 实例化:创建一个类的实例,类的具体对象。
- 对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
类的定义和实例化对象
1 | |
类有一个名为`` init()` 的特殊方法(构造方法),该方法在类实例化时会自动调用,像下面这样:
1 | |
类的实例化操作会自动调用 __init__() 方法。例如x = MyClass()时,对应的 __init__() 方法就会被调用。
- init() 方法可以有参数,参数通过 init() 传递到类的实例化操作上:
1
2
3
4
5
6class Complex:
def __init__(self, realpart, imagpart):
self.r = realpart
self.i = imagpart
x = Complex(3.0, -4.5)
print(x.r, x.i) # 输出结果:3.0 -4.5 - self代表类的实例,而非类;类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self。
继承
派生类的定义:
1 | |
子类(派生类 DerivedClassName)会继承父类(基类 BaseClassName)的属性和方法。
- BaseClassName(实例中的基类名)必须与派生类定义在一个作用域内。除了类,还可以用表达式,基类定义在另一个模块中时这一点非常有用:示例:
1
class DerivedClassName(modname.BaseClassName):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29#类定义
class people:
#定义基本属性
name = ''
age = 0
#定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
#定义构造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" %(self.name,self.age))
#单继承示例
class student(people):
grade = ''
def __init__(self,n,a,w,g):
#调用父类的构函
people.__init__(self,n,a,w)
self.grade = g
#覆写父类的方法
def speak(self):
print("%s 说: 我 %d 岁了,我在读 %d 年级"%(self.name,self.age,self.grade))
s = student('ken',10,60,3)
s.speak()
多继承
定义形式:
1 | |
需要注意圆括号中父类的顺序,若是父类中有相同的方法名,而在子类使用时未指定,python从左至右搜索 即方法在子类中未找到时,从左到右查找父类中是否包含方法。
实例:
1 | |
方法重写
1 | |
super() 函数是用于调用父类(超类)的一个方法。
类的私有属性
__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。
类的方法
在类的内部,使用 def 关键字来定义一个方法,与一般函数定义不同,类方法必须包含参数 self,且为第一个参数,self 代表的是类的实例。
self 的名字并不是规定死的,也可以使用 this,但是最好还是按照约定使用 self。
类的私有方法__private_method:两个下划线开头,声明该方法为私有方法,只能在类的内部调用 ,不能在类的外部调用。self.__private_methods。
小结:
类的专有方法:
__init__: 构造函数,在生成对象时调用__del__: 析构函数,释放对象时使用__repr__: 打印,转换__setitem__: 按照索引赋值__getitem__: 按照索引获取值__len__: 获得长度__cmp__: 比较运算__call__: 函数调用__add__: 加运算__sub__: 减运算__mul__: 乘运算__truediv__: 除运算__mod__: 求余运算__pow__: 乘方
运算符重载
可以对类的专有方法进行重载
1 | |
运行结果:Vector(7,8)
8.迭代器和生成器
迭代是 Python 最强大的功能之一,是访问集合元素的一种方式。
迭代器是一个可以记住遍历的位置的对象,从集合的第一个元素开始访问,直到所有的元素被访问完结束,只能往前不会后退。
迭代器有两个基本的方法:iter() 和 next()。
字符串,列表或元组对象都可用于创建迭代器
创建迭代器
1 | |
常规遍历迭代器
1 | |
1 | |
创建一个类作为迭代器
把一个类作为一个迭代器使用需要在类中实现两个方法 __iter__() 与 __next__() 。__iter__() 方法返回一个特殊的迭代器对象, 这个迭代器对象实现了 __next__()方法并通过 StopIteration 异常标识迭代的完成。
__next__() 方法会返回下一个迭代器对象。
示例:创建一个返回数字的迭代器,初始值为 1,逐步递增 1:
1 | |
结果:1 2
StopIteration
StopIteration 异常用于标识迭代的完成,防止出现无限循环的情况,在 next() 方法中我们可以设置在完成指定循环次数后触发 StopIteration 异常来结束迭代。
示例:在 20 次迭代后停止执行:
1 | |
生成器
在 Python 中,使用了 yield 的函数被称为生成器(generator)。
yield 是一个关键字,用于定义生成器函数,生成器函数是一种特殊的函数,可以在迭代过程中逐步产生值,而不是一次性返回所有结果。
生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
当在生成器函数中使用 yield 语句时,函数的执行将会暂停,并将 yield 后面的表达式作为当前迭代的值返回。每次调用生成器的 next() 方法或使用 for 循环进行迭代时,函数会从上次暂停的地方继续执行,直到再次遇到 yield 语句。这样,生成器函数可以逐步产生值,而不需要一次性计算并返回所有结果。
实例:
1 | |
生成器函数的优势是它们可以按需生成值,避免一次性生成大量数据并占用大量内存。
9. 多线程
10. 正则表达式
正则表达式的概念
https://www.runoob.com/regexp/regexp-intro.html
为什么使用正则表达式?
典型的搜索和替换操作要求提供与预期的搜索结果匹配的确切文本。虽然这种技术对于对静态文本执行简单搜索和替换任务可能已经足够了,但它缺乏灵活性,若采用这种方法搜索动态文本,即使不是不可能,至少也会变得很困难。
通过使用正则表达式,可以:
- 测试字符串内的模式。
例如,可以测试输入字符串,以查看字符串内是否出现电话号码模式或信用卡号码模式。这称为数据验证。 - 替换文本。
可以使用正则表达式来识别文档中的特定文本,完全删除该文本或者用其他文本替换它。 - 基于模式匹配从字符串中提取子字符串。
可以查找文档内或输入域内特定的文本。
例如,你可能需要搜索整个网站,删除过时的材料,以及替换某些 HTML 格式标记。在这种情况下,可以使用正则表达式来确定在每个文件中是否出现该材料或该 HTML 格式标记。此过程将受影响的文件列表缩小到包含需要删除或更改的材料的那些文件。然后可以使用正则表达式来删除过时的材料。最后,可以使用正则表达式来搜索和替换标记。
python中正则表达式的实现
re.match函数
尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none(匹配成功re.match方法返回一个匹配的对象,否则返回None)
1 | |
| 参数 | 说明 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等 |
示例:
1 | |
运行结果:
1 | |
稍微复杂一点的例子:
1 | |
实例执行结果:
1 | |
解释:
代码尝试从 line 中匹配一个子串,该子串的规则如下:
捕获 “are” 前面的内容和 “are” 后面的内容。在正则表达式中,括号用于创建分组,以便后续可以通过 matchObj.group(1) 和 matchObj.group(2) 来获取这两个匹配的内容。
对于给定的 line = “Cats are smarter than dogs” 这个例子:
“Cats” 匹配 (.),并保存在分组 1 中。
“are” 匹配 “are”。
“smarter” 匹配 (.?),并保存在分组 2 中。
所以,最终成功匹配的结果是:
matchObj.group() : Cats are smarter than dogs:整个匹配的字符串。
matchObj.group(1) : Cats:匹配到的第一个分组,即 “are” 前面的内容 “Cats”。
matchObj.group(2) : smarter:匹配到的第二个分组,即 “are” 后面的内容 “smarter”。
re.search函数
扫描整个字符串并返回第一个成功的匹配
1 | |
- re.match与re.search的区别
re.match 只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回 None,而 re.search 匹配整个字符串,直到找到一个匹配。
检索和替换
1 | |
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
- flags : 编译时用的匹配模式,数字形式。
前三个为必选参数,后两个为可选参数。
repl 参数是一个函数的情况:
1 | |
compile 函数
用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用
1 | |
findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
1 | |
- pattern 匹配模式。
- string 待匹配的字符串。
- pos 可选参数,指定字符串的起始位置,默认为 0。
- endpos 可选参数,指定字符串的结束位置,默认为字符串的长度
示例:
- 查找字符串中的所有数字运行结果:
1
2
3
4
5
6
7
8
9
10
11import re
result1 = re.findall(r'\d+','runoob 123 google 456')
pattern = re.compile(r'\d+') # 查找数字
result2 = pattern.findall('runoob 123 google 456')
result3 = pattern.findall('run88oob123google456', 0, 10)
print(result1)
print(result2)
print(result3)1
2
3['123', '456']
['123', '456']
['88', '12'] - 多个匹配模式,返回元组列表运行结果:
1
2
3
4import re
result = re.findall(r'(\w+)=(\d+)', 'set width=20 and height=10')
print(result)1
[('width', '20'), ('height', '10')]
re.finditer
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回
1 | |
re.split
按照能够匹配的子串将字符串分割后返回列表
1 | |
- maxsplit 分割次数,maxsplit=1 分割一次,默认为 0,不限制次数。
示例:
1 | |
导入自己写的Python文件作为自定义库
只需要将需要引用的函数或变量定义在一个.py文件中,然后在其他.py文件中通过import语句导入即可。
注意,当你导入一个自定义库时,Python会执行该库中的所有顶层代码。这意味着如果在自定义库中有一些不是函数或类定义的代码,它们也将会被执行。因此,最好将不需要立即执行的代码放在条件语句中。
1 | |
import导入一个库
- 可以通过库的名称引用库中的类:
例如,假设有一个名为my_module.py的Python文件,其中定义了一个类MyClass,你可以使用以下方式引用这个类:
1 | |
- 另一种方式是使用from关键字,这样你可以直接使用类名,而不需要使用库名称来引用类:
1
2
3
4
5
6
7
8# 从my_module库导入MyClass类
from my_module import MyClass
# 创建MyClass的实例
obj = MyClass()
# 调用MyClass的方法
obj.some_method()